A clustering for Erlang on Xen
——————————
Background
The standard Erlang/OTP distribution layer suffers from a number of shortcomings that hinder its use for Erlang on Xen: every node of an Erlang/OTP cluster has to maintain connections to all other nodes limiting the practical cluster size, epmd daemon feels out of place, tight coupling with DNS is not always desirable.
The Erlang on Xen instance foam may have thousands of relatively short-living nodes. The clustering layer of Erlang/OTP cannot be borrowed to manage them effectively. A new clustering layer is needed.
The present document provides an overview of the new clustering layer. The overview must be detailed enough for developing a working prototype.
In addition to Erlang/OTP the new clustering layer draws ideas from MPI[1], AMQP[2], ZeroMQ, KVMFS[3].
Reviewers of the document are encouraged to provide their comments. Specifically, the following topics may can not be fully resolved without such comments:
- The security model. The proposed approach is similar to Erlang/OTP’s cookies. It is enough?
- The proposed clustering is not compatible with Erlang/OTP. How serious an issue is this?
- What failure modes have we overlooked?
- What cloud stacks should we target in addition to OpenNebula?
Scope
The clustering layer should provide the following two primary functions: internode message passing — the ability to send messages to processes on other nodes, and remote process and node monitoring — the ability to generate events when a process or an entire node goes away.
The clustering layer relies on the underlying layers, such as 9p connections, and intergration with other systems to implement the functions. All other functions needed for running a distributed application are built on top of these two primary functions. Examples of functions not included in the clustering layer: globally registered processes, named nodes, process supervision trees.
All expectations of the clustering layer with respect to underlying layers and external systems must be explicitely documented.
Self-imposed Constraints
Do not change or extend semantics of Erlang, the language.
Instance migration should not interfere with clustering functions.
The clustering should work in public clouds, such as Amazon EC2.
Public and private clouds
Erlang on Xen may be deployed in private as well as public clouds. Public clouds, such as Amazom EC2, impose a set of constraints mostly on the communication infrastructure. For example, Amazon EC2, allows only TCP, UDP, and ICMP traffic.
Private clouds that allow unrestricted access to Dom0, the privileged Xen domain, do not have these constraints.
The clustering layer should be designed with public clouds in mind. When a functionality available only in private clouds is required it should be clearly marked as ‘private clouds only’ and a fallback mechanism should be available for public cloud deployments.
The Model
The unit of computation in Erlang is a ‘process’. Each process is identified by a unique Pid.
A process is executed within confines of a container called a ‘node’. A unique node identifier can be obtained trivially given a Pid. A process cannot be migrated to another node. A node can execute many thousand processes concurrently.
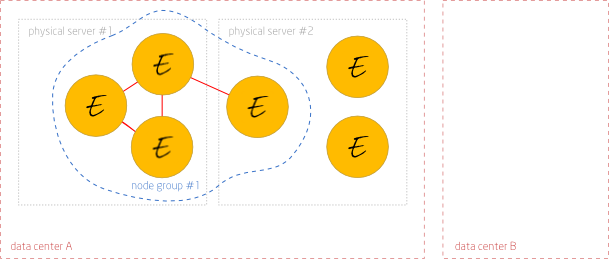
Each node runs on a physical server. A physical server can host dozens nodes. Nodes can be migrated between them. The id of the node must survive migration.
Nodes are attached to a network. Each node has a unique network address that survives migration between physical servers.
Each physical server belongs to a ‘data center’. Network connections within a single data center are more reliable and of much lower latency than connections between data centers.
Each node belongs to a single ‘node group’. Only nodes that belong to the same node group may exchange messages. Communication between processes that belong to different node groups may be implemented by higher-level mechanism, such as persistent queues.
Nodes that belong to the same node group are necessarily runs on physical servers of a single data center.
The estimated number of model elements in a typical cluster:
- Data centers: 1-5
- Physical servers: 1-100 per data center
- Nodes: 1-20 per physical sever
- Processes: 50-1000 per node
Everything is unreliable
The clustering layer does not assume that the underlying communication infrastructure is reliable. Rather, the opposite assumption is made. The same goes with reliability of nodes. They may and will fail from time to time and the clustering layer should be prepared to deal with it.
All elements of the model are unreliable. The following three types of failures are possible:
- Node crashes/hangs
- A node crashes due to a software error. Usually, the condition can be readily detected and handled without a delay. Sometimes, a node may ‘hang’, for example, by entering an infinite loop, and the detection of the condition becomes more complicated. This type of errors are expected to gradually become less frequent. ( MTBF = 100 days).
- Physical server crashes
- All nodes currently running on the affected physical node go away. The condition may be detected by appropriate event may be generated. ( MTBF = 500 days).
- Connectity lost temporarily
- Nodes on a physical server lose ability to communicate with other nodes. The condition may be detected and reported by the network. The connectivity is restored within 100s. ( MTBF = 500days).
The model assumes that all failures follow Poisson distribution.
Nodes talk 9p
All communication between nodes happens over 9p-connections. Such connections are opened between each pair of nodes that need to exchange process messages or other information related to clustering. 9p-connections between nodes may be closed after a certain period of inactivity.
The 9p layer uses a generic transport interface [4]. If a transport connection underneath a 9p-connection is lost, the 9p layer must attempt to reestablish the transport connection. The simplest kind is a transport connection implemented by 9p_tcp module.
A separate transport for communication between data centers may be added. The inter-datacenter transport may bundle multiple 9p-messages together, have a special behaviour with respect to timeouts, etc.
The uname field of 9p-attach request should contain node id and group names separated by ‘:’. For a successful 9p-attach either node id should be equal to the parent id of the node or the group name should be the same.
The transport connection should not provide redundancy such as multiple IP addresses or port numbers. The redundancy is introduced in a predictable way by mounting several service instances at the same point in the local hierarchy.
The only failure that may bubble up from 9p layer is a ‘mount loss’. It happens when all connections supplying a given mounting point drop and can not be reestablished. Local processes may subscribe to the mount loss event indicating the subtree they are interested in. The subscribed processes receive a message when the mount loss event happens. The subscriptions use the standard monitor()/demonitor() interface with the Type set to ‘9p’ and Item set to the mounting point.
The format of data read/written to synthetic files exported over 9p can be both human- and machine-readable. When a node is mounted from Linux for monitoring and administration purposes the data format must be textual and easily parsable. When a node is mounted for message passing, the format must be binary for efficiency. The practical approach is to distinguish between the two by the version of 9p protocol used. ‘9p2000.L’ version will then singify a Linux client and ‘9p2000’ version – Erlang on Xen clients.
How nodes find each other
Each node has a globally unique identifier represented as an atom, such as ‘96f3c8f3-62a1-42d9-85f1-bf8b230e5c39’. The identifier coincides with the virtual machine identifier used by the Xen hypervisor and the cloud management stack. The identifier is retrieved from xenstore at /local/domain/(domid)/vm. Note that the node identifier survives the instance migration.
If no active 9p-connection exists between the nodes, then the clustering layer should consult a discovery service to retrieve the transport parameters for a new 9p-connection.
All nodes of a node group share a discovery service. The service is accessed via 9p by mounting /disc. The service may be mounted multiple times for faster response. Each instance of the discovery service knows transport parameters of nodes of a given node group only. A loss of the /disc mount constitutes a general ‘loss of connectivity’ failure. As a reaction to the loss of connectivity, the node usually shuts down all functionality except a small post mortem process that reports the situation if the connectivity is restored.
Birds of feather
Each node belongs to a single node group. A node group constitutes a communication domain for internode message passing. The name of the node group — an atom — can be retrieved by calling erlang:node_group().
When a new node is started the configuration data passed to it contains, inter alia, the node group and discovery service specifications. Thus all nodes of a given group share a discover service.
The node group is passed in the uname field of 9p-attach requests. If the node group in the request does not coincide with the local node group the request is rejected. This mechanism is similar to the magic cookie of Erlang/OTP. This is the only authorization/authentication scheme used by the new clustering layer.
The first node of the new group of node is called a ‘seed’ node. The seed node does not receive the discovery service location from the parent. It is responsible for starting a discovery service itself. The supervisor usually runs on a seed node. A seed node can be started in another data center.
Spawning a new node
Spawning new computing nodes requires interfacing with a particular cloud infrastructure. The de-facto standard for cloud infrastructure interface is EC2 API. This API is supported by most cloud stacks, including the primary testing platform for Erlang on Xen clustering – OpenNebula.
Standard cloud stacks may be too sluggish to unlock the full potential of Erlang on Xen. A future extension of the clustering layer may replace many (or most) functions of a cloud stack and talk directly to Xen hypervisors and OpenFlow-enabled network elements.
Every node can access the external cloud management stack and start a new node. A complete configuration information is passed from the parent to the child node upon startup. A child node must not have to consult any network services, such as DHCP, during the boot sequence [TODO: DHCP sometimes is unavoidable]. The parent node passes the following information to its children:
- node id
- parent node id
- group (same as the parent’s group, except seed nodes)
- ip address (depends on policy)
- discovery service locations (except seed nodes)
- EC2 interface parameters
Passing an ip address to the child node as a configuration item is the fastest way to spawn the node. Unfortunately, it is not always possible, especially in the public clouds. IPv6 has a nice property of allowing selection of a random addresses for new nodes. In any case, the parent node should be able to start child nodes and then obtain ip addresses assigned to them by the cloud management stack.
After spawing new nodes, the parent node should update the discovery service with the transport information for the new nodes. To do this, the parent node should ‘create’ files in /disc directory and write transport information into them [TODO: this may be slow for a thousand new nodes].
The parent may mount /cc on the child node even if the child is a seed node. Then the parent may issue reconfiguration and other commands by writing to files such as /cc/panel. One possible command that can be written to /cc/panel is ‘shutdown’. A complete list of commands is not specified yet.
How messages travel between nodes
Let’s assume a message Msg is being sent to a remote process Pid. The remote process runs on the node NodeId and has a local address of LocAddr there. LocAddr is sufficient to complete the delivery once the message reaches NodeId. LocAddr is either a rank of the process or a registered name. NodeId and LocId can be trivially derived from Pid.
The addressing scheme may be later extended by allowing registered names for nodes. Even further, multiple nodes may have the same registered name and a message addressed to a (registered) process on a named node may reach the process of one of them. If needed, this function can be implemented on top of a simple remote message passing.
Each node participating in the internode message exchange must export two synthetic filesystem /proc and /rproc. Writing to synthetic files /proc/(rank) constitutes sending messages to corresponding processes. If LocId is a registerd name (atom), then messages should be written to /rproc/(name). The message is serialized using the standard erlang:term_to_binary() function. The framing is provided by the 9p layer. A single call to 9p-write corresponds to a single message sent. Note that the maximum message size should be set high to allow large message through.
9p-connections between nodes and Fids of remote processes should be cached and closed after certain period of activity or according to a similar policy.
Well-known services
9p server embedded in Erlang on Xen can only export top-level directories that contain synthetic files. Each directory’s behaviour is implemented by an Erlang module with a defined interface [4]. The list of well-known clustering services that can be exported by a node:
- /proc
- The synthetic directory contains a list of files that numeric names corresponding to ranks of processes running on the node. For instance, the file /proc/137 corresponds to the process with the Pid of <0.137.0>. Writing to the such file is mapped to sending message to it. Each 9p-write sends a single message to the process. The message body must be converted to a binary using erlang:term_to_binary(). Exported by all clustered nodes.
- /rproc
- The same as /proc by files correspond to registered names of processes. For example, the file /rproc/code_server allows sending messages to a process registered as code_server. Exported by all clustered nodes.
- /disc
- A node discovery service. The synthetic directory contains files named after nodes in the communication domain. Reading such files results in a transport configuration needed to reach the node. For example, reading the file /disc/96f3c8f3-62a1-42d9-85f1-bf8b230e5c39 may yield {’9p_tcp’, {{10,0,0,111}, 564}}, the transport configuration needed to connect to NodeId of ‘96f3c8f3-62a1-42d9-85f1-bf8b230e5c39’. Exported only by discovery servers.
- /cc
- A control center. The synthetic directory contains files that allows top level operations on the node. The only file envisioned now is /cc/panel and the only command that can be written to it is ‘shutdown’. More files and commands to be added in the future.
- /link, /rlink
- TODO
- /mon, /rmon
- TODO
Links and process monitors
The clustering layer allows linking and monitoring remote processes.
A subscription to link/monitor notification is created by mounting /link name on the remote node and writing {link,Pid} to it. Pid is the process that wants to receive the notification. /rlink direcotry should be used for registered names. Monitor subscriptions are created similarly by using /mon and /rmon directories.
The monitor notifications are passed to subscribed processes using a general message passing mechanism. The link signals are delivered by writing {’EXIT’,Reason} to /link/(rank) or /rlink/(name) files.
A node goes down
The node monitoring relies entirely on the external systems, such as OpenNebula. The cloud management stack is the place to retrieve information about failing physical servers and which nodes were affected by such failure.
Sometimes a loss of connection to a given node may mean that the node crashed. This information may provide advice to the clustering layer but is not the primary node monitoring method.
The application may implement its own node monitoring scheme in addition to the standard monitor_node()/demonitor_node() interface.
Node monitoring subscriptions and events are dependent on a particlular cloud management stack in use. The prototype should use OpenNebula interfaces. Each node interested in the node monitoring communicates with the cloud management stack directly.
MPI: A Message-Passing Interface Standard, Version 2.2, 2009.
OASIS Advanced Message Queuing Protocol (AMQP) Version 1.0, 2012.
KvmFS: Virtual Machine Partitioning For Clusters and Grids, 2007.
9p-based filesystems, v1.2, Cloudozer, 2012.