Training neural network using genetic algorithm
———————————————–
Over the last few years we observed the raise of artificially intelligent applications, which showed almost super-human ability to solve difficult problems. A closer look reveals that deep neural networks is what drives this wave.
Any neural network must to be trained to become useable. For example, given a classification problem we may need to have thousands of examples for each class we want a neural network can discern. A preparation of a training dataset is usually costly and sometimes infeasible.
This post describes how to train a neural network to play a board game — Gomoku — without any expert knowledge, simply by making it play against itself.
Gomoku is an ancient board game. Players make moves by placing black and white stones on a 15×15 board. The player who has 5 or more stones in a row wins. The black player makes the first move in the center of the board. Thus blacks get a serious advanatge in the game. Recently different constrains have been introduced to balance the chances of whites to win. For simplicity reason I did not take them into account.

On the Figure 1 below you may see that the neural network I built for choosing best moves has less than a thousand neurons. The input layer represents a position in the board. Four convolutional layers extract features form the input layer and the subsequent layer of 12 neurons sums up all extracted features. The last layer represented by a single neuron rates of the current position.
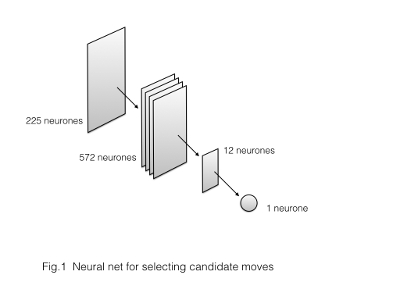
The higher the output, the more advantage a player has against its opponent at the particular position on the board. The features were selected manually. Thus their weights should not be learned. All we need to tune are the coefficients in the last hidden layer that summaries the features.
To optimise weights in the last layer I used a genetical approach or ‘a law of the jungle’ — only the strongest survive. I generated a lot of neural networks with different initial weights and let them play against each other.
Let us consider a pair of agents. They play two games switching sides. Let us define WW as the vector of weights of the winner and Wl as the one of the loser. δW is a small random deviation. Depending on the score, I apply the following rules:
If agent one won both games (score 2 : 0) then
- Ww ← Ww
- Wl ← Ww + δW
If the score was 1.5 : 0.5 then
- Ww ← Ww
- Wl ← Wl + δW
If score was 1 : 1 then
- Ww ← Ww
- Wl ← Wl
The above rules are quite simple. They resemble the famous Conway’s Game of Life. In both cases, a few simple rules lead to unexpected richness.
Below you may see a simulation obtained for 100 different agents, which played 30,000 games against each other in random order.
Click here to see the animation
An agent starts with random weights. Then it rambles in the 12-dimensional space eventually forming clusters of similar agents. Each cluster cluster represents a (suboptimal) solution to the problem.
A quick recap:
1. Traditional training of a neural networks requires to have a large training dataset. The dataset is set of pairs {X,Y}, where X is an input and Y is the correct (expert’s) output. These are hard (or impossible) to obtain.
2. The described exampe uses a genetic algorithm that stochastically modifies weights of two neural networks depending on the result of the game between them. The strongest agents cluster together as their networks are trained.
Tweet comments powered by Disqus